

Contributed by: Annus Zulfiqar, University of Michigan
Challenge: Modern virtual switches cannot efficiently offload millions of dynamic wildcard rules to SmartNICs because hardware caches are too small, leading to high miss rates and costly software fallbacks.
Solution: Gigaflow introduces pipeline-aware sub-traversal caching with Longest Traversal Matching (LTM), decomposing vSwitch pipeline traversals into reusable segments that maximize SmartNIC table utilization and significantly improve cache efficiency.
Impact: This approach dramatically increases rule-space coverage and hit rates while reducing latency and software fallbacks, enabling scalable, line-rate packet processing for AI-scale and cloud workloads on P4-programmable SmartNICs.

The Challenge: Virtual Switches at Their Limits
Programmable networks have transformed how data centers and edge clouds enforce policies, connect end-host tenants (VMs and containers), and steer traffic throughout the network fabric. At the heart of this transformation are virtual switches (vSwitches), such as Open vSwitch (OVS), which provide flexible, programmable packet-processing pipelines configured using OpenFlow.
But vSwitches face a scaling wall. As line rates climb to 100–400 Gbps per link and workloads grow more dynamic (think AI training clusters or edge inference), CPUs struggle to keep up with the performance demands of modern end-host networking. To relieve the host CPUs from infrastructure responsibilities, operators are increasingly turning to SmartNICs. These NICs integrate P4-programmable table pipelines with on-chip memory, enabling traffic classification and steering at line rate.
However, existing SmartNIC caches are tiny—often accommodating just 10–50K wildcard entries—compared to the millions of rules needed to cover modern workloads. This creates high miss rates and forces much of the traffic back to software, eroding the benefits of hardware offload.
The Insight: Pipeline-Aware Locality in Virtual Switches
Traditional wildcard caches like Megaflow treat each packet’s complete journey through the vSwitch pipeline as a single traversal. The first packet in a flow is resolved through all pipeline tables; the result (a wildcard match plus an action) is cached, and later packets can skip the slow-path pipeline.
This works well in software—where single-table caches are key to performance—but wastes precious hardware cache space and underutilizes the multi-table architecture available in today’s SmartNICs. To fully utilize the underlying SmartNIC architecture, we look deeper into the structure of these vSwitch pipelines and note that many flows share common sub-traversals of the pipeline. For example, flows may take the same L2 and L3 lookups but diverge at ACL rules. Megaflow, on the other hand, caches each individual traversal as a separate entry, duplicating shared segments.
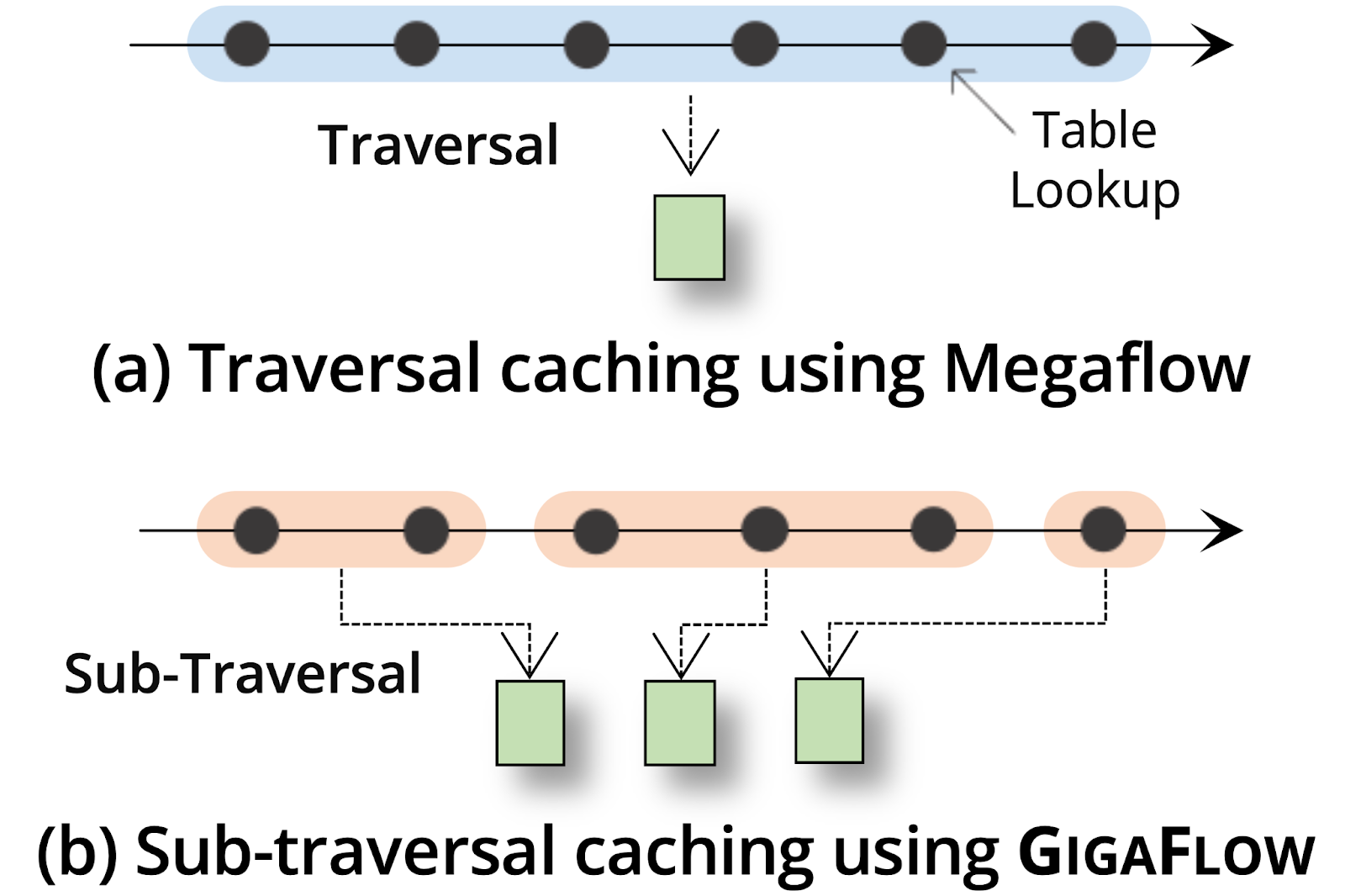
Figure 1: (a) A traversal is a complete sequence of table lookups through the vSwitch pipeline that generates a Megaflow rule. (b) A sub-traversal is a subset of these lookups within a traversal, capturing smaller, reusable segments shared across multiple flows.
Based on this observation, Gigaflow introduces a new form of caching using sub-traversals. Instead of caching entire traversals as separate cache entries in Megaflow, Gigaflow decomposes them into smaller, reusable segments or sub-traversals that capture a new form of locality, called pipeline-aware locality: overlapping sequences of lookups that occur across many flows.
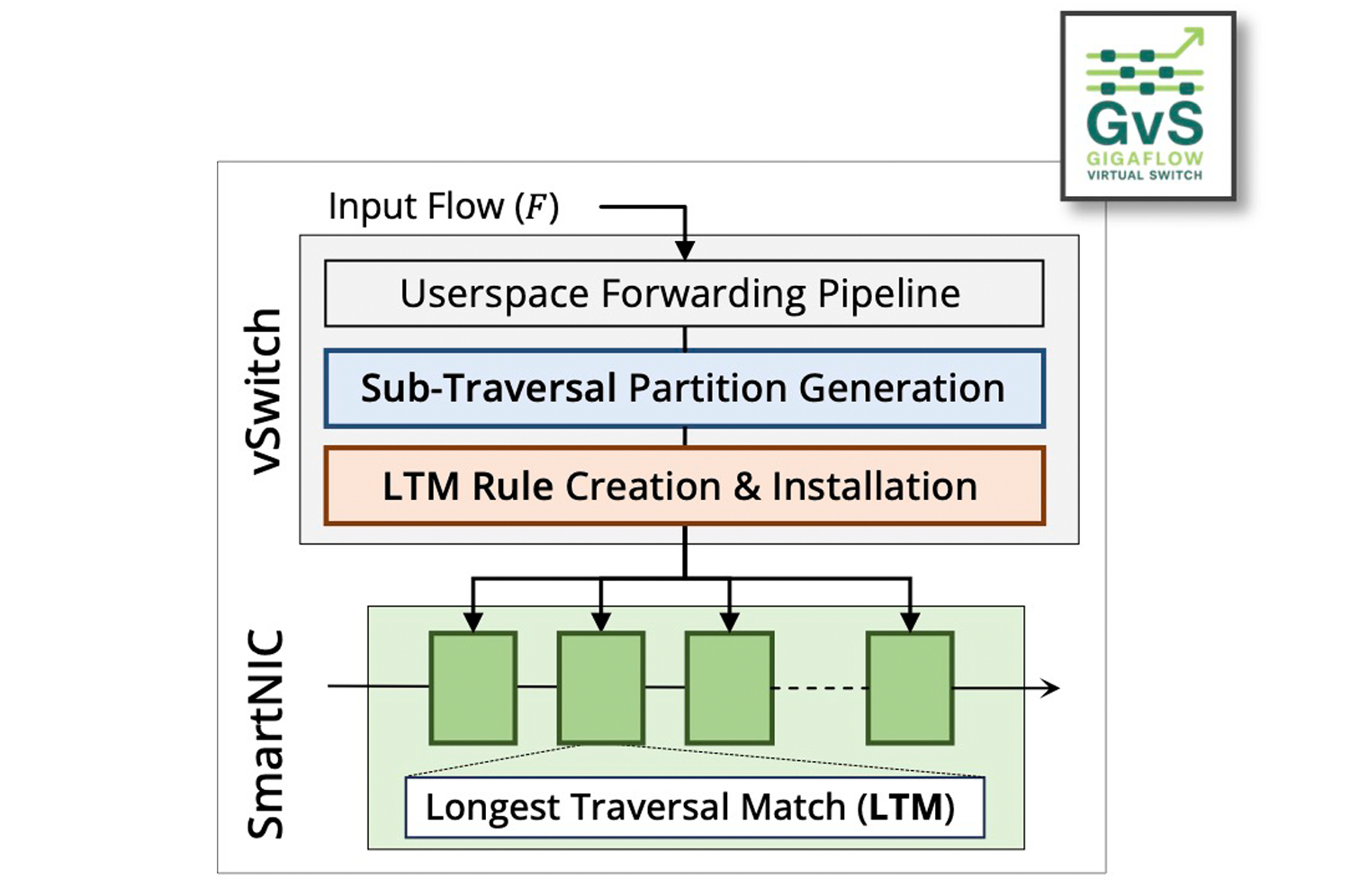
Figure 2: Gigaflow—a new temporary memory storage method for virtual switches—helps direct heavy traffic in cloud data centers caused by AI and machine learning workloads. Rather than storing data packets as they arrive, Gigaflow instead breaks up packets into shared rule segments—processing steps multiple packets have in common. The system then identifies the order of rules, finds the most frequently used rules, and makes those easy to reach.
The Mechanism: Longest Traversal Matching (LTM)
Gigaflow maps sub-traversals onto the limited tables available inside SmartNIC pipelines (e.g., 4–8 stages). To ensure lookup correctness, it introduces Longest Traversal Matching (LTM), a new cache lookup scheme implemented in P4 on RMT-style architectures.
Partitioning for cache generation:
When generating cache entries from OVS traversals, Gigaflow automatically partitions traversals at disjoint header boundaries (e.g., between Ethernet, IP, and TCP fields). This maximizes the cross-product rule space coverage in Gigaflow tables by maximizing the sub-traversal sharing opportunity.
Cache lookup in Gigaflow:
- LTM prioritizes sub-traversals that span the most tables, ensuring the most specific path is taken—similar in spirit to Longest Prefix Match in IP routing.
- Each sub-traversal is tagged with a table ID, ensuring that packets progress through the correct sequence of cached segments, even when there are overlaps.
Implemented in P4, LTM tables are simple: each stage matches on a tag (table ID) and relevant packet headers, then updates the tag (next expected sub-traversal’s table ID), modifies the packet based on actions, and forwards to the following LTM table. This design makes Gigaflow naturally compatible with today’s P4-programmable SmartNICs and FPGAs.
Results: More Rule Space Coverage, Radically Fewer Misses
Our prototype integrates Gigaflow into OVS and offloads to a P4-programmable FPGA SmartNIC. Using real vSwitch pipelines (OVN, Antrea, OFDPA) and realistic workloads (Classbench, CAIDA), we find:
- Up to 51% higher hit rate (25% average) vs. Megaflow
- Up to 90% fewer misses, reducing costly software fallbacks
- Up to 450x more rule-space coverage with fewer entries
- Lower latency: up to 30% reduction in end-to-end packet processing delay
While sustaining line rate performance and utilizing just 38W of on-chip power on an Alveo U250 data center accelerator.
Why It Matters for P4
Gigaflow is fundamentally about using the pipeline structure itself as a source of locality to cache flows efficiently. This makes P4 central to Gigaflow’s design:
- P4 defines the pipeline: by exposing policies as ordered match-action tables, P4 programs provide the structure Gigaflow exploits.
- P4 enables portability: LTM is expressed in portable P4 constructs—tags, priorities, ternary matches—making it implementable across FPGAs and ASIC SmartNICs.
- P4 empowers verification. By modeling sub-traversals in P4, we can reason about correctness and revalidation incrementally, rather than caching arbitrarily.
Gigaflow shows that domain-specific programmability via P4 is not just about expressiveness, but also about enabling new system architectures.
Building Gigaflow as an Open Source Codebase
As part of our commitment to the community, we are also building Gigaflow into a publicly available artifact through Google Summer of Code (GSoC), 2025. This summer, Advay Singh, a Senior from the University of Michigan, Ann Arbor, joined our team and implemented Gigaflow for the AMD/Xilinx Alveo U250 data center accelerator SmartNIC, integrating its low-level device APIs into Open vSwitch.
This effort was central to our roadmap for making Gigaflow broadly accessible—lowering the barrier for practitioners, researchers, and students to experiment with sub-traversal caching on real hardware—and we have actively showcased this progress through a P4 Dev Days talk and a live demo at the P4 Workshop, fostering broader engagement and adoption within the programmable networking community.
Learn More
- Research Article: [ASPLOS’25] Gigaflow – Pipeline-Aware Sub-Traversal Caching for Modern SmartNICs
- GitHub: Gigaflow prototype
- P4 Developer Day Recording: Gigaflow | Pipeline-Aware Sub-Traversal Caching for Modern SmartNICs ⬇️